MQTT Sparkplug Solution for Industrial IoT Using EMQX & Neuron



Table of Contents
Introduction
Sparkplug is an MQTT-base communication protocol designed specifically for industrial automation and IoT applications. To implement a Sparkplug solution, two essential components must be in place. One is an MQTT broker for message distribution and management; the other is an edge node to connect local devices to the broker to enable real-time data processing and analysis.
In this article, we will use EMQX, an open-source distributed MQTT broker, and Neuron, an edge IIoT connectivity server, to provide a scalable and robust platform for building Sparkplug solutions. We will delve into the architecture of Sparkplug solution and the roles that EMQX and Neuron play.
The Role of EMQX
EMQX is used to create an MQTT topic namespace that conforms to the Sparkplug specification. The Sparkplug namespace defines the structure and content of the MQTT messages that device will publish and subscribe to. EMQX ensures that all messages sent to and received from the Sparkplug namespace are properly formatted and conform to the Sparkplug specification.
Learn more about EMQX: EMQX Enterprise: Enterprise MQTT Platform At Scale
Try EMQX Enterprise for FreeConnect any device, at any scale, anywhere.
The Role of Neuron
Neuron is used to connect edge devices to the Sparkplug namespace on the EMQX broker. Neuron acts as a gateway, collecting data from local sensors and controllers and publishing it to EMQX using the Sparkplug payload format. Neuron also subscribes to messages in the Sparkplug namespace and forwards them to local devices as needed.
Learn more about Neuron: Neuron: Industrial IoT Connectivity Server
Try Neuron for Free
The New Role of EMQX and Neuron Together
EMQX and Neuron can be used together to create a unified namespace for industrial IoT applications. A unified namespace is a common naming convention for MQTT topics that allows devices and applications to communicate with each other regardless of location or protocol. All devices and applications use the same MQTT topic hierarchy based on a common set of naming conventions and data models. This allows devices to discover and communicate with each other without the need for complex routing or translation mechanism.
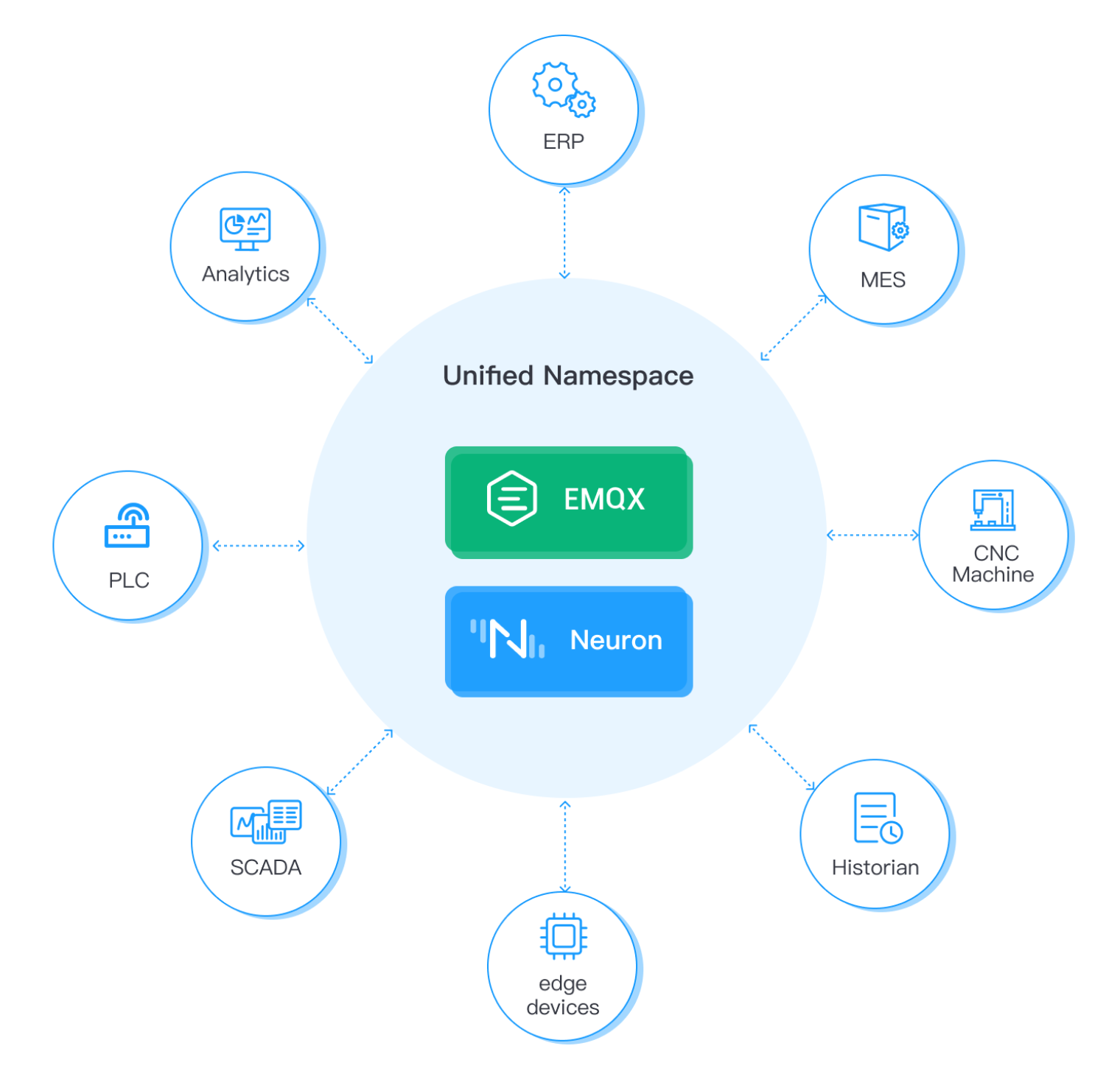
EMQX can be configured to support a unified namespace by defining a topic hierarchy that conforms to the naming conventions and data models used by the devices and applications in the system. For example, the topic hierarchy could include topics for device data, control commands, alarms, and events, all organized in a standardized way that allows devices and applications to discover and interact with each other.
Neuron can be configured to support a unified namespace by using the same naming conventions and data models as the MQTT broker. This allows Neuron to integrate seamlessly with the rest of the IoT system, enabling devices to communicate across locations and protocols.
Sparkplug Solution Architecture
The MQTT Sparkplug solution using EMQX and Neuron can be designed as a three-tier architecture. All devices and applications equally connected to a unified namespace in the diagram above can be classified into two layers. The bottom layer is the data producers, while the top layer is the data consumers. The middle layer is where EMQX and Neuron facilitate data exchange between data producers and consumers.
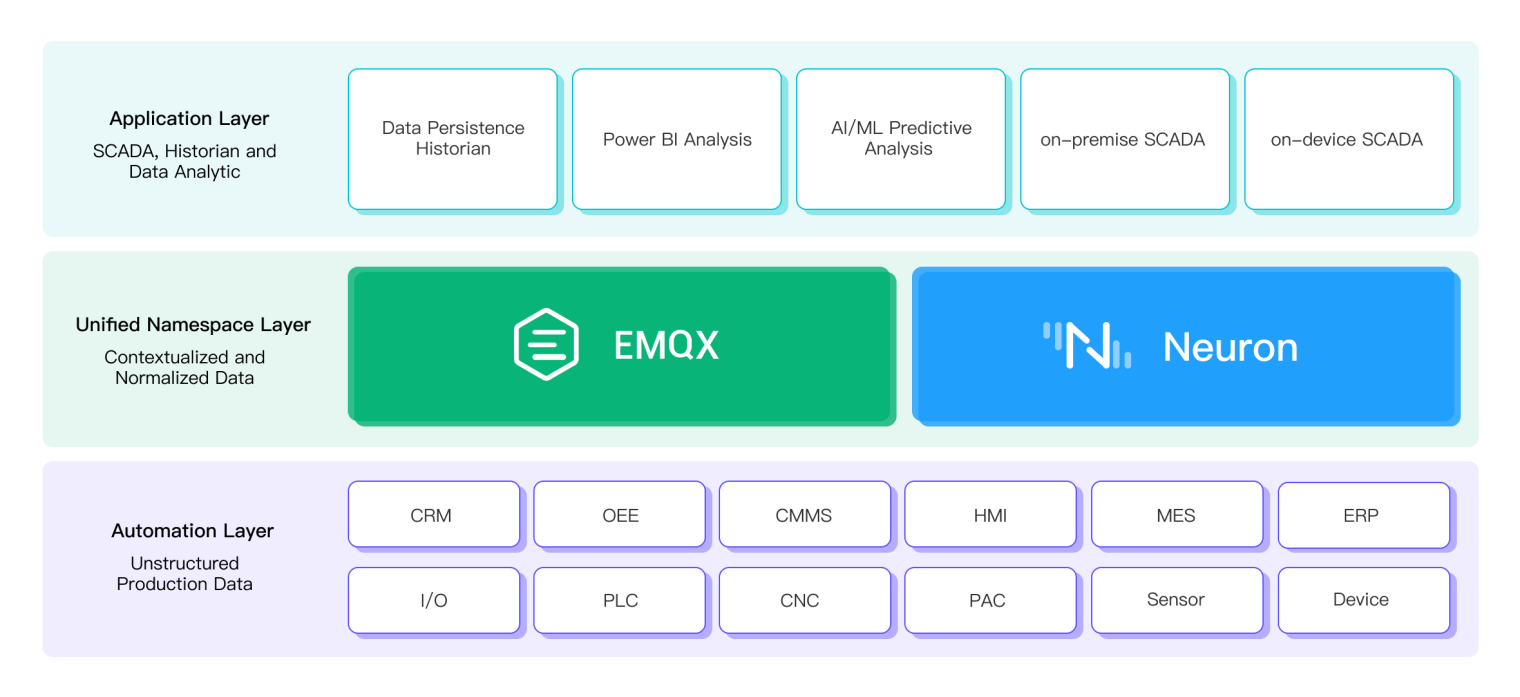
The Automation Layer: This layer consists of devices and applications that produce large amounts of raw and unstructured data during automated production. These devices and applications can be located on the factory floor and data center.
The Unified Namespace Layer: This layer consists of an EMQX MQTT broker and a Neuron gateway, where Neuron assists the sensors or devices in publishing the Sparkplug message to the EMQX, which receives the data from the producers and forwards it to the subscribers. EMQX is responsible for maintaining the state of the system, including the devices and their associated data.
The Application Layer: This layer consists of applications that consume data from the unified namespace layer and use it to perform analysis, monitoring, control, and other functions. These applications can be located on-premises or in the cloud, depending on the requirements of the system.
We will walk through each layer in the following sections.
Automation Layer
The Automation Layer can generate information about the entire automated production process in the factory. This information comes from the following devices or systems.
Field devices: The devices, CNC machines, sensors, and actuators used to collect and control data in the physical world.
Control devices: The PLC, PAC, DCS, and various controllers that manage the operations of the field devices. These devices are responsible for executing the control algorithms and communicating with the field devices.
Supervisory systems: The devices such as HMI (Human-Machine Interface) and SCADA (Supervisory Control and Data Acquisition) systems.
Information systems: Databases, data historians, MES (Manufacturing Execution Systems), ERP (Enterprise Resource Planning), and other software applications that store and analyze the data collected from the above devices or systems.
In day-to-day production, the field devices collect data from the physical world and send it to the control devices. The control devices process the data and send commands to the field devices to control their behavior. The supervisory systems monitor the performance of the control devices and provide feedback to the operators and information systems. Finally, the information systems collect and store data from all the lower-level devices and systems and provide access to the information for other enterprise systems. This flow of information enables the automation system to operate effectively and efficiently. But this information is raw and unstructured data that must be normalized and contextualized for further analysis.
Unified Namespace Layer
The Unified Namespace Layer collects all the unstructured and raw data from the Automation Layer and adds context to it. This is the process of data normalization and contextualization which means bringing together data from many different sources into a single information source with a timestamp. All of this data is organized and accessible in a consistent and standardized way, regardless of the data source or format.
This normalized and contextualized data incorporates all relevant information for a specific purpose, such as equipment performance, environmental conditions, production output, and other metrics important to industrial operations. In other words, contextualization provides a single, meaningful, unified view of all the data within an organization. By leveraging this contextualized data, industrial organizations can gain a comprehensive and holistic view of their operations, enabling them to better informed decisions and optimize their processes for greater efficiency and profitability.
Application Layer
The Application Layer is where the applications can use the contextualized data to perform analytics, such as predictive maintenance and AI(Artificial Intelligence)/ML(Machine Learning), and make informed decisions about factory operations. These applications can subscribe to specific data points or device nodes to receive real-time updates, allowing factories to respond quickly to changes in the production process.
Contextualized data can improve the quality of data used in AI/ML models. By providing additional context and metadata, AI/ML models can better understand and interpret data, reducing errors and improving accuracy. In addition, contextualized data also enhance the predictive capabilities of AI/ML models. By providing additional context, models can make more accurate predictions about future events or outcomes.
Conclusion
In summary, by using EMQ and Neuron together in the Sparkplug solution, contextualization can be easily implemented and help ensure that data is shared accurately and consistently across the system. This solution not only facilitates the discovery and communication between devices and applications, irrespective of their distinct naming systems, but it also empowers analytical applications such as AI/ML, BI business analytics, and predictive control. As a result, decision-makers can have more precise insights and actionable outcomes, enabling them to make informed decisions based on reliable data and analysis.